
Navigation/Menü: Links auf weitere Seiten dieser Website sowie Banner
Modellierungsverfahren
Das Modellierungsverfahren für das Berliner City Modell nutzt die Berliner Messdaten (für die Analyse) und die COSMO-DE Daten (für die Prognose, in Plan) als Prediktoren für das Downscalingsmodell. Nachdem Downscaling wird für das Berliner Stadtgebiet ein Datensatz mit einer Auflösung von 5-10 m generiert.
In dieser Studie wird die Neuro-Fuzzy ( Kombination von Fuzzy-Systemen und Neuronale Netzen) Methode „Active Learning Method“ (ALM) für das Downscaling angewendet. Die einzelnen Schritte der Neuro-Fuzzy-Modellerstellung sind in der folgenden Abbildung wiedergegeben (Taheri Shahraiyni u. a., 2005).

Abb. 1 Flussdiagramm der Active Learning Method“ (ALM)
Im ersten Schritt wird ein ‚Eingabe-Ausgabe-Datensatz‘ zusammengestellt. Im Folgenden sei ein einfaches Beispiel mit nur zwei Eingangsgrößen x1 und x2 und einer Ausgangsgröße y betrachtet (Abbildung 2). Im zweiten Schritt werden die Daten auf xi-y-Ebenen projiziert, wobei i für die Anzahl der Eingangsgrößen steht, um im dritten Schritt ein Polynomial an die vorhandenen Punkte anzupassen.
 Abb. 2 Arbeitsschritte der Active Learning Method“ (ALM)
Abb. 2 Arbeitsschritte der Active Learning Method“ (ALM)
Bei der Active Learning Method wird die Ink Drop Spread (IDS) Methode (Bagheri Shouraki und Honda, 1997) angewendet. Hierbei wird jeder Punkt einer x-y-Ebene als Lichtquelle mit umgebendem Lichtkegel betrachtet (siehe Abbildung 3). Mit wachsendem Abstand zum jeweiligen Datenpunkt sinkt die Helligkeit des Lichtkegels und geht gegen Null. Das Helligkeitsmuster verschiedener Datenpunkte kann sich hierbei auch überlagern und neue Helligkeitszentren bilden. Die IDS Methode wird auf jeden Datenpunkt der x-y-Ebene angewendet. Der Radius eines jeden Lichtkegels wird dann so lange vergrößert, bis der gesamte Definitionsbereich der Variablen auf der x-y-Ebene abgedeckt ist (siehe Abbildung 3.Mitte und Rechts).

Abb. 3 Die Ink Drop Spread (IDS) Methode
Schließlich werden durch Berechnung des Schwerpunktes in y-Richtung implizite nichtlineare Funktionen erstellt.Die erstellten nichtlinearen Funktionen für das hier gezeigte Beispiel sind in Abbildung4 wiedergegeben.

Abb. 4 Nichtlineare Funktion
Bei der Takagi-Sugeno Methode (Takagi und Sugeno, 1985) wird die Zu-gehörigkeitsfunktion mit Hilfe beliebig vieler linearer Funktionen angenähert (Abbildung 5). Auf diese Art und Weise wird für jede x-y-Ebene eine nichtlineare Funktion konstruiert. Im vierten Schritt wird die Güte der konstruierten nichtlinearen Funktion für jede x-y Ebene anhand des Root Mean Square Error (RMSE) bestimmt. Dieser wird über den Vergleich zwischen gemessenen Daten und modellierten Daten entlang der erstellten Funktion ermittelt.
Abb. 5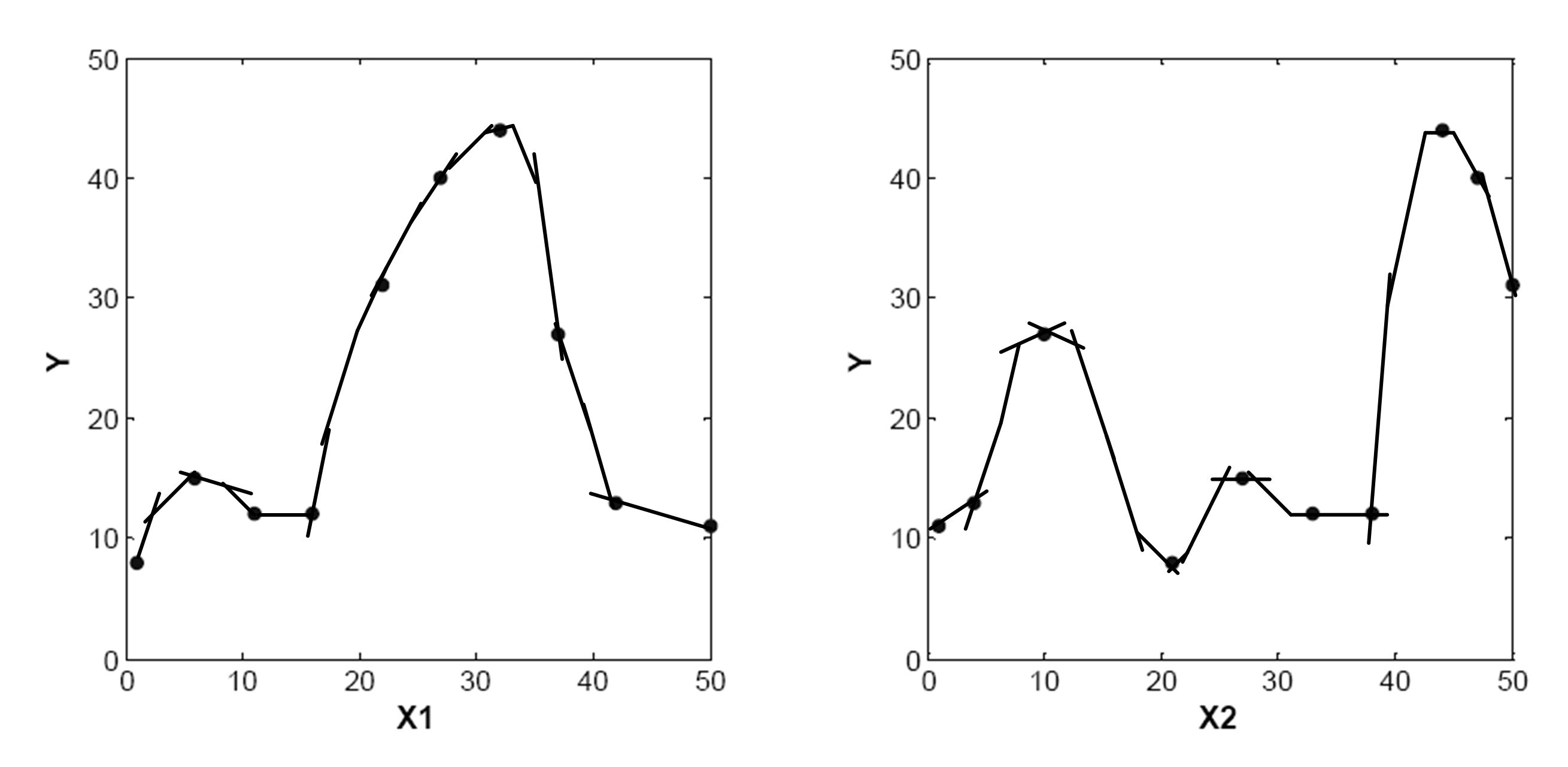
Gemäß des bestimmten RMSE wird im nächsten Schritt x1 oder/und x2 als Prediktor gewählt und die entsprechende Zugehörigkeitsfunktion abgespeichert. Im sechsten Schritt werden die Fuzzy-Regeln generiert, wobei es nach dem ersten Durchlauf erst eine Regel gibt. In unserem Fall lautet diese y=f(x1). Dabei ist f(x1) die im Schritt fünf gespeicherte Funktion. Die Fuzzy-Regeln werden im nächsten Schritt angewendet und der Modellfehler (d.h. der Root Mean Square Error der aus dem Vergleich zwischen den gemessenen und den vom Modell simulierten Werten resultiert) wird bestimmt. Der ermittelte Fehler wird in Schritt 8 mit einem zu Beginn festgelegten Fehlergrenzwert verglichen. Anhand dessen entscheidet sich, ob die Modellerstellung fortgeführt wird (Schritt 9) oder beendet ist (Schritt 10). Der Modellfehler soll in diesem Beispiel oberhalb des Grenzwertes liegen, es folgt also Schritt 9. Hier wird mit Hilfe eines heuristischen Suchverfahrens (Takagi und Sugeno, 1985) der Definitionsbereich der Parameter geteilt.
Es sei noch gesagt, dass der betrachtete Fall mit nur zwei Eingangsgrößen x1 und x2 ein sehr vereinfachtes Beispiel ist und die Modellerstellung und die entstehende Modellstruktur bei der Verwendung mehrerer Eingangsgrößen und dem Vollzug mehrerer Teilungsschritte beliebig kompliziert wird.
Nach Abschluss der Trainingsphase wird die Güte des Modells geprüft. Hierfür wurden die Daten zu Beginn in Lern-und Testdaten unterteilt. Mit den Lerndaten wurde das Modell trainiert. Die nach der Lernphase folgende Modell Validierung ist der Prozess, bei dem die Eingaben, die nicht für den Lernprozess verwendet wurden, d.h. die Testdaten, das erstellte Modell durchlaufen, um zu prüfen, wie genau das Neuro-Fuzzy Modell die entsprechenden Ausgangswerte wiedergeben kann. Als Ausgabe der Modell Validierung erhält man den Root Mean Square Error des erstellten Modells, den sogenannten Checking Error. Das Modell wird in einem letzten Schritt entsprechend so angepasst, dass der Checking Error möglich klein ausfällt.
In unserer Studie werden die Messdaten von 9 Wetterstationen des Stadtmessnetzes des Instituts für Meteorologie der FU-Berlin, 5 Wetterstationen des Deutschen Wetterdienstes sowie 6 Wetterstationen der Firma Meteomedia als Prediktoren verwendet um die Temperaturverteilung in der Stadt Berlin mit ca. 200 Messpunkte einer Messkampagne zu simulieren. Die Simulationen (Fuzzy Regeln) werden nach jeder Messrunde (alle 20 Minauten) modifiziert.
Ein weiterer wichtiger Aspekt bei dieser Modellierung, sind die Landnutzungsdaten, so wird jedem Messpunkt eine Landnutzungsklasse zugeteilt.

KONTAKT
MILIEU -
Centre for Urban Earth Systen StudiesFreie Universität Berlin
FB Geowissenschaften
Institut f. Meteorologie
Carl-Heinrich-Becker-Weg 6-10 12165 Berlin
Dr. Lydia Dümenil Gates
+49 (0)30 838-71179
lydia.dumenilgates@met.fu-berlin.de